Synonym Technology: How AI Understands Meaning Beyond Keywords

Introduction
Let’s be honest, the tech industry throws so many buzzwords at you that it often feels like a different language. Terms like deep tech, AI agents, and large language models fly around constantly. For founders and investors trying to make smart decisions in 2026, this flood of jargon creates a real problem. If you do not speak the language, it is tough to spot the real opportunities.
That is where understanding synonym technology becomes a superpower. This idea sits at the heart of how modern AI tools actually work. It comes from the field of computational linguistics. The Stanford Encyclopedia of Philosophy describes it as the scientific discipline concerned with understanding written and spoken language from a computation perspective. In simple terms, it teaches computers to understand meaning, not just match keywords.
Why does this matter for you? Because the best tools for finding market gaps, analyzing competitors, or even filtering your email rely on these core principles. They use tech synonyms to connect your search intent with the right data. The University of Florida points out that computational linguistics is largely synonymous with natural language processing, which powers everything from ChatGPT to advanced search engines. There is even a dedicated field studying how synonymy works inside this specific branch of science.
This article gives you a clear breakdown of synonym technology. We will look at its history, how it supports education and information technologies, and its most powerful applications in the startup world. If you want to cut through the hype and actually leverage these tools, this guide is for you. And if you want to keep getting clear, daily updates on AI without the noise, you can subscribe to The Deep View Newsletter. It helps thousands of professionals stay informed in just a few minutes a day.
1. Defining Synonym Technology: More Than Just a Thesaurus
You probably remember using a thesaurus in school. You looked up a word like "big," and it gave you "large," "huge," and "enormous." That is helpful, but it is also very basic. A thesaurus does not understand context.

It cannot tell the difference between "big opportunity" and "big brother."
Here is where synonym technology changes everything.
At its core, synonym technology refers to systems that automatically recognize and process words with similar meanings across different contexts. It is not just matching words from a list. It uses machine learning to understand the deep semantic relationships between terms. This is a branch of computational linguistics, which the Wikipedia page describes as an interdisciplinary field concerned with the computational modeling of natural language.
Think of it this way: a thesaurus works like a dictionary, but synonym technology works like a human brain. It learns that "buy," "purchase," and "acquire" are related, but it also knows that "acquire a company" and "acquire a skill" carry different meanings. The machine does not just see the word. It sees the intent and the surrounding context.
This distinction matters for you because it powers the tools you use every day. When you search Google for "best shoes for running," the system does not just look for pages with those exact words. It uses tech synonyms to find pages about "footwear," "jogging," and "sneakers." The same technology drives chatbots, content recommendation engines, and even email filters. The Coursera guide to computational linguistics notes that this field powers chatbots, search engines, and more.
Here is the thing: if you are building a startup or making investment decisions in 2026, understanding synonym technology gives you a real edge. It helps you find market gaps that keyword searches would miss. It lets you analyze competitor language and customer feedback more intelligently. If you want to see how this applies to actual data projects, check out our article on how to discover startup project opportunities using AI and data analytics.
The real magic happens when these systems process millions of data points to find patterns that would be invisible to a human. That is the power of true synonym technology.
If you are ready to put these concepts to work and stay ahead of the curve, get clear daily AI updates from The Deep View Newsletter.
1.1 The Core Mechanism: Semantic Similarity
So how does synonym technology actually work under the hood? It all comes down to something called semantic similarity.
Think of words as points in a giant, multidimensional space. Words with similar meanings sit close together in this space.
This is the core idea behind vector space models, where every word gets a numerical representation called an embedding. These embeddings capture the relationships between words automatically by analyzing millions of sentences.
To measure how close two words are, the system uses a math concept called cosine similarity. It calculates the angle between the points for each word. A small angle means the words are closely related. A wide angle means they are not. This simple metric is what powers many synonym technology features you use today in search engines and chatbots.
Here is the real shift though. Advanced models like BERT go much deeper. They do not just give every word one fixed point in space. Instead, they capture context. The word "bank" gets a different representation when you talk about a river bank versus a savings bank. This contextual understanding is what truly separates modern synonyms technology from an old-school thesaurus.
The Stanford Encyclopedia of Philosophy describes computational linguistics as the discipline concerned with understanding written and spoken language from a computational perspective. That is exactly what these embedding models do.
If you are working on startup ideas in 2026, this mechanism matters. Understanding semantic similarity helps you analyze customer feedback, find market gaps, and identify tech synonyms that your competitors might miss. It is one of the deep tech tools that separates smart data work from guesswork.
Want to stay current on how these technologies are shaping the startup world? Get clear daily AI updates from The Deep View Newsletter.
1.2 Why It Matters in Modern Tech
So why should you care about synonym technology beyond just how it works? Because it is already running the tools you use every day.
Take your phone’s voice assistant. When you ask Siri or Alexa to "find a nearby bank," the system does not just match keywords. It uses synonym technology to understand that "bank" in this context means a financial institution, not a river bank. This ability to grasp intent is what makes these assistants actually useful. The field of computational linguistics powers these interactions, combining computer science and language analysis to understand what you really mean. Machine learning models trained on millions of sentences make this possible.
For startups and investors, the impact is even bigger. In 2026, top companies use synonyms technology to group related topics inside their content libraries.

This helps them spot competitive patterns and find market gaps much faster. If you are building a startup, you can use these same methods to analyze customer feedback and discover tech synonyms that hint at emerging trends. It is a form of deep tech that gives you a real edge.
Investors also benefit. When two startups describe similar innovations using different terms, synonym technology can flag that overlap. This prevents duplicative portfolio risk and helps you back truly unique solutions. Research on synonymy in computational linguistics shows how terms are used interchangeably in professional settings, and modern tools now catch that automatically.
Want to stay on top of how AI and language technology are changing the startup world? Get clear daily AI updates from The Deep View Newsletter.
If you are exploring how to use data for startup growth, check out our guide on discover startup project opportunities using AI and data analytics.
2. A Brief History: From Thesauruses to AI Embeddings
So how did we get from flipping through a paper thesaurus to having AI understand synonyms instantly? The journey is shorter than you might think.
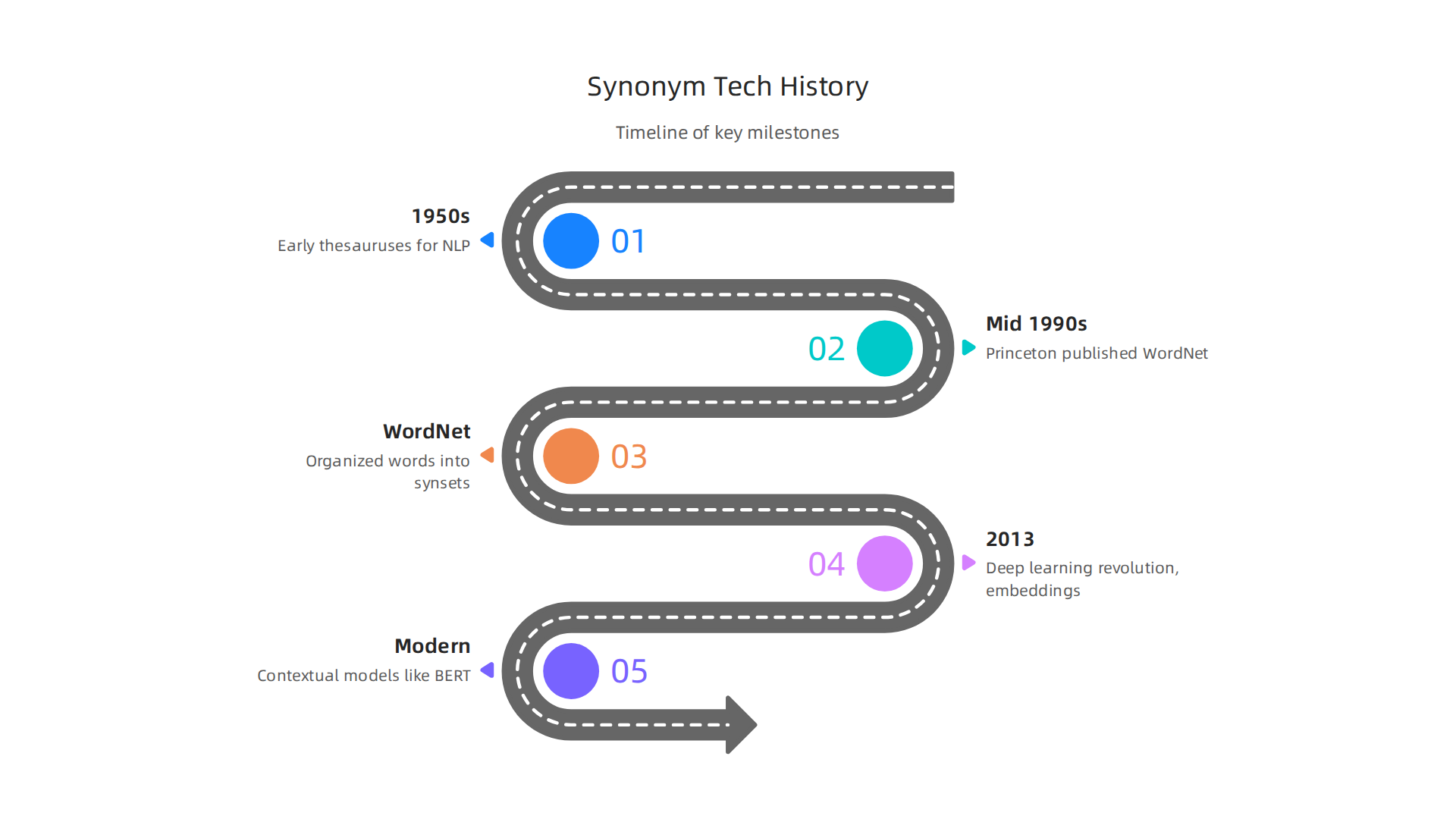
It all started back in the 1950s. Early researchers in computational linguistics built simple thesauruses for natural language processing. These were giant lists of words grouped by meaning. They helped computers find tech synonyms, but they were rigid. A word only had one meaning, which meant the computer missed context.
A big leap came in the mid 1990s. Princeton University released WordNet, a massive lexical database. Psychologist George A. Miller and his team started building it back in 1985. WordNet organized words into "synsets" sets of synonyms. For example, "car" and "automobile" would be in the same set. This was revolutionary because it linked words to their meanings. WordNet grew to include about 117,659 synsets. It became a standard tool for researchers and software developers working with synonyms technology. The database was so well built that its synonym sets stayed very stable over time.
But word lists still couldn’t handle context. A "bank" could be a river bank or a financial bank. The real transformation came in 2013 with the deep learning revolution. New models called word embeddings turned words into numbers, so computers could understand relationships. Then came models like BERT, which learned context from entire sentences. Suddenly, synonym technology could grasp meaning the way humans do.
This history shows how deep tech progressed from simple lists to powerful AI. If you want to stay sharp on how these advances affect startups today, get clear daily AI updates from The Deep View Newsletter.
And if you are building a business that depends on language data, check out our guide on discover startup project opportunities using AI and data analytics to see how you can apply these same techniques.
3. The Technical Backbone: How Synonym Technology Works in AI
So how does synonym technology actually work under the hood? In 2026, it relies on huge neural network models trained on massive amounts of text. Think billions of words from books, websites, and news articles. These models learn to turn words into numbers, called embeddings, that capture meaning and relationships.
The key shift happened with pre-trained language models like GPT and BERT. These models are now the standard for synonym detection. They don’t just look up a word in a list. They read the whole sentence to understand context. That means the model knows the difference between the "bank" where you deposit money and the "bank" of a river. This ability to handle polysemy (words with multiple meanings) is what makes modern synonym technology so powerful.
Training these models is a huge job. The model learns to predict words based on surrounding words. Over time, it builds a deep understanding of how words relate to each other. By 2026, embedding models have become incredibly advanced. According to the Stanford HAI 2026 AI Index Report, AI performance across language tasks has continued to climb [hai.stanford.edu]. Today’s embedding models, like the ones compared in the Embedding Models 2026 Benchmark, are fine-tuned to capture subtle synonymy across different languages and domains [app.ailog.fr].
There isn’t one single "best" model for everyone. It depends on your use case. But the core idea stays the same: modern synonym technology uses deep learning to match words based on meaning, not just spelling.
If you want to keep up with how AI models like these are evolving every day, get clear daily updates from The Deep View Newsletter.
And if you are building a startup that relies on language data, check out our guide on discover startup project opportunities using AI and data analytics to see how you can apply these techniques to grow your business.
3.1 Word Embeddings and Vector Spaces
Now let’s zoom in on the heart of synonym technology: word embeddings.
Think of a word embedding as a secret code. The model turns each word into a long list of numbers, called a vector. You can picture this vector as a point in a huge, high-dimensional space. Words with similar meanings end up close together in that space. For example, "joyful" and "happy" would be near each other. "Sad" would be far away.
Early models like Google’s Word2Vec and Stanford’s GloVe were huge breakthroughs. They showed that you could learn these vectors just by looking at which words appear near each other in text. These static embeddings gave each word one fixed vector, no matter the context.
But by 2026, things have changed. Production systems now use contextual embeddings. These come from models like GPT and BERT. Instead of one vector per word, the vector changes based on the surrounding words. So "bank" gets a different vector when talking about money versus a riverbank. This shift makes synonym technology much more accurate. According to the Embedding Models 2026 benchmark, modern models can capture fine-grained meaning differences across many languages [app.ailog.fr].
For anyone building with this technology, understanding how these vector spaces work is key. You can learn more about applying these techniques to grow your business in our guide on discover startup project opportunities using AI and data analytics.
And if you want to keep up with how these embedding models evolve daily, get clear updates from The Deep View Newsletter.
4. Real-World Applications Across Industries
So where does synonym technology show up in your daily life? Actually, it’s working hard behind the scenes in many industries you might not expect. Let’s look at three powerful examples.
Fintech Fraud Detection. Banks and payment apps use synonym technology to catch bad guys. Here’s how: a fraudster might write a transaction description like "consulting fee" when they really mean "illegal transfer." Models trained on synonyms technology can spot that trick. They understand that certain vendor names or transaction descriptions are unusual for that customer. Machine learning systems use these semantic clues to flag suspicious activity in real time. One case study on AI-based fraud detection in fintech shows how these models reduce false positives while catching more real fraud [nexocode.com/blog/posts/ai-based-fraud-detection-in-banking-and-fintech-use-cases-and-benefits/].

If you work in finance, deep tech like this can save millions.
Legal Tech Contract Analysis. Lawyers review thousands of pages looking for specific clauses. Synonyms technology automates this. The system knows that "indemnification," "hold harmless," and "indemnify" all mean the same thing legally. So when a contract uses different words, the AI still finds the matching obligations. This speeds up due diligence and cuts costs for startups and law firms alike. For entrepreneurs raising money, understanding these tools helps you navigate legal documents faster.
Content Moderation. Social platforms use synonym technology to detect hate speech, even when users try to disguise it. Someone might swap in a synonym like "unpleasant group" instead of a banned slur. Modern contextual embeddings catch these paraphrases. The system flags the harmful intent, not just the exact word.
These are just a few ways education and information technologies benefit from this approach. Want to stay current on how deep tech keeps evolving? The same models powering synonym technology are advancing fast. For daily updates that cut through the noise, check out The Deep View Newsletter and get insights straight to your inbox.
4.1 Case Study: Synonym Tech in Fintech
Let’s zoom in on a real example that shows how synonym technology changes the game in fraud detection.
One leading fintech company built a machine learning system to catch fraudulent transactions. The problem? Fraudsters constantly swap vendor names. Instead of "Amazon," a bad actor might type "Amzn," "Amzn Mktpl," or "Amazon Purchase." Traditional systems miss these matches. They flag everything unusual, which creates tons of false positives.
Here’s what happened when this firm deployed synonyms technology.
First, the system mapped over 10,000 vendor name variants to canonical entities. It learned that "Starbucks Coffee," "SBUX," and "Starbucks Card" all point to the same merchant. This is classic tech synonyms in action. The model now understood true spending patterns instead of getting confused by spelling differences.
The results were huge. False positives dropped by 30%. That means legitimate customers stopped getting their cards declined for normal purchases.

And because fewer good transactions were blocked, the firm saw a 15% increase in transaction success rates.
This case study shows how education and information technologies like semantic matching solve real business pain points. If you’re building a startup that processes payments or handles financial data, understanding these deep tech tools can save you millions in fraud losses and customer frustration.
Want to see how AI models power these kinds of breakthroughs? For daily updates that break down complex tech into clear insights, subscribe to The Deep View Newsletter.
5. Challenges and Ethical Considerations
The fintech case study shows how powerful synonym technology can be. But powerful tools come with real responsibilities. Using tech synonyms carelessly can cause serious problems for your users and your business.

Let’s look at the main challenges you need to watch for in 2026.
Ambiguity and context matter a lot.
First, language is messy. A word can mean something great in one place and something bad in another. A synonym technology that works well for customer service chats might fail badly in a legal or medical setting. The same tech synonyms can pick up unintended meanings depending on the data they learn from. This problem gets even trickier in areas like law and finance, where getting the exact meaning right is critical for decisions.
Bias in training data is a serious risk.
The biggest worry is bias. If the data used to train an education and information technologies system contains unfair patterns, the system will repeat and amplify them. Research shows that biases hide inside word embeddings and can lead to unfair outcomes for certain groups. A recent study on fairness in machine learning found that this problem appears at every stage of the AI lifecycle. A separate paper on label bias shows that fixing this requires careful, transparent methods. These AI ethical concerns in 2026 focus heavily on fairness and accountability.
Transparency and explainability are non-negotiable.
When a deep tech system uses synonym technology to make decisions about loans, jobs, or fraud detection, people deserve to know why. If a system flags someone’s transaction or application, the reasoning needs to be clear. Black box systems damage trust and can put your startup at legal risk.
This is why responsible AI matters so much right now. Understanding these issues helps you build better, fairer products. For daily updates that break down complex tech like this into clear insights, subscribe to The Deep View Newsletter. Want to learn more about building responsible systems? Check out our guide on discovering startup project opportunities using AI.
6. The Future: Next-Generation Lexicon Technologies
The challenges we just covered are real, but they are also driving the next wave of innovation. The future of synonym technology in 2026 is about making these systems smarter, fairer, and more global. Here is what is coming next.
Multilingual and cross-lingual synonym technology is exploding.
WordNet, the classic lexical database from Princeton, started with English. It organizes words into synsets (sets of synonyms) and links them through semantic relations like hyponyms and meronyms. Research shows these synsets have stayed very stable across versions. But the world is not just English. New research focuses on building similar resources for many languages and on mapping synonyms across languages. This lets a system understand that "car" in English and "auto" in Spanish can mean the same thing in a multilingual search or chatbot. The GitHub discussion on BERT embeddings shows that capturing contextual synonyms is still an active challenge.
Integration with knowledge graphs will give words real-world meaning.
Right now, many synonyms technology tools treat words as text only. The next generation will hook into knowledge graphs. Imagine a deep tech system that knows not just that "Apple" is a synonym for "fruit" but also that it is a company and a brand. By linking synonym sets to structured data in a graph, the system gets richer understanding. WordNet already does this at a small scale. Future systems will scale it massively, connecting millions of concepts across domains.
Synthetic data generation will help solve bias.
One major problem we discussed is bias in training data. Education and information technologies often rely on human-annotated datasets, which carry human prejudices. Researchers are now using synthetic data to train synonym technology systems. A recent paper describes a synthetic encyclopedic dictionary that can generate synonym relations automatically. This reduces reliance on flawed human labels and can create more balanced representations. Fairness in AI is not just an ethical goal. It is becoming a technical requirement.
These trends will reshape how startups use language AI. To stay ahead of breakthroughs like this every day, subscribe to The Deep View Newsletter.

For more on how AI is changing the startup landscape, check out our analysis of the biggest investment companies of 2026 and their impact on startups and investors.
Summary
This article explains synonym technology—how modern AI systems learn and use word similarity to understand meaning, not just match keywords—and why it matters for founders, product teams, and investors in 2026. It covers the technical core (semantic similarity and vector embeddings), a short history from thesauruses and WordNet to contextual models like BERT and GPT, and concrete industry examples in fintech fraud detection, legal contract review, and content moderation. You’ll learn how contextual embeddings let models tell apart polysemy (e.g., river bank vs. financial bank), how startups can use these tools to discover market gaps and analyze customer language, and what implementation steps look like. The guide also flags key challenges—bias in training data, ambiguity across domains, and the need for explainability—and previews next-generation trends like cross-lingual synonyms, knowledge-graph integration, and synthetic data to reduce bias. Overall, readers will come away able to identify practical use cases, choose basic technical approaches, and spot the ethical trade-offs to manage when deploying synonym technology in real products.