Build Your Modern Data Pipeline for Startup Success

In today’s fast-moving world of startups and investments, having the right information at the right time is super important. Think about it: how do founders know what products to build? How do investors decide where to put their money? They need facts, not guesses. This is where a modern data pipeline becomes critical.

Without a strong data pipeline, information can be messy and hard to use. It’s like having many puzzle pieces scattered everywhere. Startups get data from customer actions, website visits, sales, and more. Investors look at market trends, company performance, and funding rounds. All these are different pieces of data.
A data pipeline helps gather all these bits of information. It cleans them up and puts them in order so you can perform data analyse. This organized data then becomes useful for what is data analytics. For example, a 2026 report showed that even in big areas like financial services, having a good data pipeline is key for using cloud services and AI, according to the State of Cloud and AI for Financial Services. This makes a big difference for making smart decisions.
Good data pipelines turn all those small, fragmented signals into clear insights. This helps startups make better choices about their products and how to grow their business. For investors, it means they can do better checks on companies before investing, feeling more confident about their decisions. It’s truly at the frontiers of computer science, making sure information works for us.
This guide will walk you through everything important about modern data pipelines. We will look at how they are built, what parts they have, how to keep your data safe through good governance, how to make them grow with your company, and even a checklist for choosing the right tools and vendors. It’s all about making sure you can trust your data and make smart moves.
Understanding data analytics is also crucial for finding new opportunities. You can learn more about how to Discover Startup Project Opportunities Using AI and Data Analytics. To stay even more informed on the latest tech changes, especially in AI, consider subscribing to The AI Newsletter Worth Reading.
Why Data Pipelines Matter for Startup Growth and Investment Scouting
A strong data pipeline helps make sure the right information gets to the right people fast.
This speed is super important for startups to grow and for investors to make smart choices. The market for Data Pipeline Startups: The Complete 2026 Market Guide is booming in 2026, showing just how vital this technology has become for businesses.
Think about product teams and Go-to-Market (GTM) teams at a startup. Product teams need to know quickly if new features are working well, if customers are happy, or if changes are needed. GTM teams need to see what marketing campaigns bring in the most customers and which strategies are most effective. A good data pipeline makes this possible by taking raw customer actions, website clicks, and sales figures from many different places. Then, it quickly cleans and changes this data into clear, easy-to-understand insights. This speedy process, known as consistent ingestion and transformation, drastically cuts down the time it takes for these teams to understand what’s happening. This means product updates can happen faster based on real user feedback, and marketing efforts can be adjusted in real-time to get better results. For example, using AI-Powered Sales and Marketing Tools with well-prepared data can really boost a startup’s growth and help them perform better data analyse.
For investors, a reliable data pipeline is a goldmine. When they look at a startup, they don’t just want stories; they want to see clear evidence of success and potential. The pipeline helps create investor-ready dashboards that are always up-to-date. These dashboards show key numbers like customer growth, sales trends, user engagement, and how well the business is truly doing. This makes due diligence, the careful process of checking a company before investing, much smoother, faster, and more trustworthy. Investors can rely on the data they see, which builds strong confidence in their decisions. If you want to see how important presenting data clearly is, especially during fundraising, you can check out this video on Funding Fundamentals & Frictionless Data Rooms. Having verified and transparent data helps in making crucial funding decisions, a topic explored by organizations like the Charlie Kirk Data Foundation.
What happens if startups don’t pay enough attention to their data pipeline? This is where common failure modes come in. Without good "pipeline discipline," data becomes fragmented. This means information is scattered across many different systems and departments, making it almost impossible to get a full and accurate picture. Imagine trying to solve a complex puzzle with pieces missing and others stuck in completely different rooms. Also, metrics can quickly become stale, meaning the numbers you’re looking at are old and no longer reflect the current business situation. Using old, inaccurate data for new, important decisions can lead to big mistakes, wasted money, and countless missed chances. It also makes it incredibly hard for startups to prove their worth to potential investors. Ensuring strong Data Security and Compliance Risk Forecast is also a crucial part of preventing these problems and maintaining data integrity.
Ultimately, a well-managed data pipeline is crucial for turning raw, scattered information into valuable, actionable insights. It helps startups make quick, smart decisions and assures investors of their growth potential, pushing the frontiers of computer science by showing us what is data analytics truly capable of achieving in the business world.
A well-managed data pipeline helps turn raw information into useful insights. But how fast do you need those insights? This question leads us to two main ways of handling data: real-time processing and batch processing.

Choosing the right one is a big deal for any startup, affecting costs, how complex your system is, and how quickly you can react.
Real-time (Streaming) Data Processing
Think of real-time processing, also called streaming, like a constant flow of water. Data comes in and is processed right away. This means you get insights almost instantly. Imagine seeing exactly how many people clicked a button on your app just seconds after they did it. This kind of speed is very useful for things like:
- Catching fraud: Spotting strange money moves as they happen.
- Live dashboards: Showing you sales numbers or website visitors right now.
- Quick feedback: Knowing if a new feature works or breaks immediately.
Many new systems are built to handle "massive volumes of fast changing data in real time," which truly pushes the Big Data Review. This approach helps businesses quickly understand "what is data analytics" capable of, letting them respond to changes in the moment.
Batch Data Processing
Batch processing is different. It’s like collecting water in a bucket all day and then pouring it out at night. Data is gathered over a certain time, like an hour, a day, or a week. Then, all that data is processed together in one big group. This method is often cheaper and simpler to set up. It’s great for:
- Daily or weekly reports: Like how many sales you made yesterday or last month.
- Payroll: Calculating everyone’s pay at the end of a pay period.
- Looking at old information: Analyzing trends over a long time.
Systems often support both streaming and batch methods, allowing users to switch easily depending on their needs, as explored in discussions on Radioelectronic and Computer Systems, 2025.
Choosing for Your Startup
When picking between real-time and batch, startups need to think about a few things:
- How fast do you need to know? If quick action is key, real-time is better. If knowing by tomorrow is fine, batch works well.
- Your budget: Real-time systems can cost more to build and run because they need to be always on and handle data constantly. Batch systems can be more cost-effective.
- How complex can your system be? Real-time setups are usually more complex to make and fix if something goes wrong. If you have a small team, starting simpler with batch might be better.
To really get the most out of your data pipeline and figure out "what is data analytics" best for your startup, you might even consider ways to Discover Startup Project Opportunities Using AI And Data Analytics.
Hybrid Models
Actually, many startups don’t pick just one. They use a mix of both! This is called a hybrid model. For example, they might use real-time for very important data like new customer sign-ups. Then, for less urgent things like website visitor logs, they might use batch processing. This helps them balance speed and cost. Topics in computer science often cover these kinds of setups, including "Lambda architecture" and other hybrid approaches for data processing. This is a common discussion in fields like CS Special Topics in Fall 2026 and advanced research into Hybrid Processing Architectures. By combining the best parts of both, startups can get the insights they need without spending too much or making things too complicated. This forward-thinking approach truly pushes the frontiers of computer science for business insights.
To stay updated on how AI and other tech trends are shaping data processing and startup growth, consider subscribing to The AI Newsletter Worth Reading for clear daily updates from The Deep View Newsletter.
After learning about different ways to process data, let’s look at the actual parts that make up a modern data pipeline.
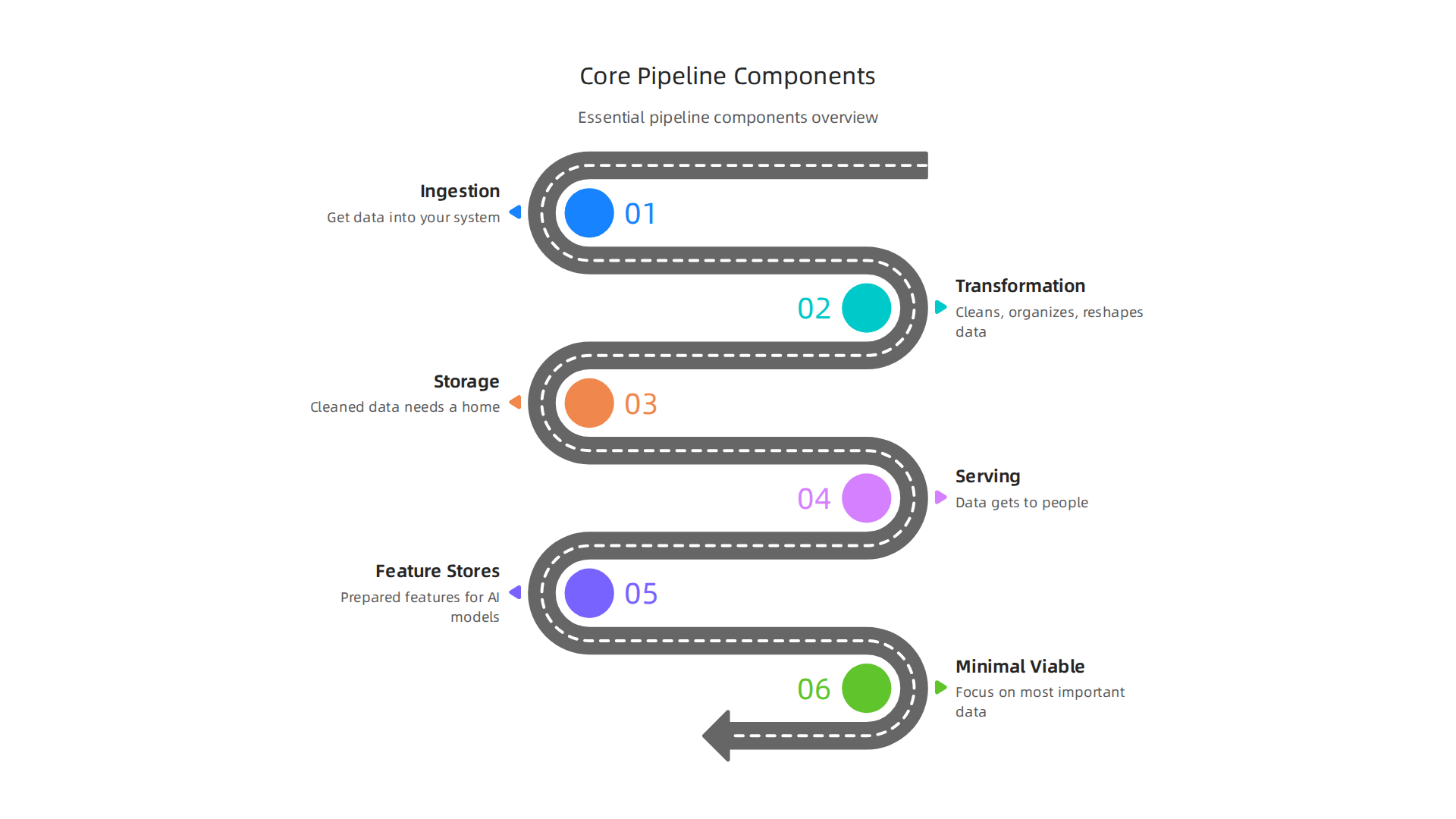
Think of it like building a house; you need different pieces to make it strong and useful.
Ingestion
First, you need to get the data into your system. This step is called ingestion. Imagine it like a funnel where all your raw information pours in from different places. These places could be your app, your website, or other tools you use. Special connections, often called "connectors," help pull this data in smoothly, making sure no important information is left behind.
Transformation (ETL/ELT)
Once the data is in, it’s usually not ready to be used right away. It might be messy, incomplete, or in the wrong format. That’s where transformation comes in. This step cleans, organizes, and reshapes the data so it makes sense. There are two main ways to do this:
- ETL (Extract, Transform, Load): Data is pulled out of its source, changed right away, and then put into its final spot.
- ELT (Extract, Load, Transform): Data is pulled out, put into a storage area first, and then changed. This approach is often more flexible for modern data setups, especially with big data.
Many tools exist to help with this, giving businesses many choices for their data pipeline needs in 2026. A proper ETL tools comparison helps you weigh old-school batch processing against newer, faster options.
Storage
After transformation, the cleaned data needs a home. This is the storage part of the data pipeline. You might hear about data lakes and data warehouses:
- Data Lake: This is like a big, open field where you can store all your data, raw or processed. It’s flexible and can hold many different types of information.
- Data Warehouse: This is more like a very organized library. Data here is structured and neatly arranged for quick reporting and analysis.
The choice depends on how you plan to use your data for various needs.
Serving
Finally, there’s the serving layer. This is how the processed and stored data gets to the people or systems that need it. This is where what is data analytics truly shines, as insights are shared through dashboards, reports, or fed into other applications. This step makes sure your data analyse efforts actually help people make smarter decisions quickly.
Feature Stores and ML-Ready Analytics
For startups looking to use AI and machine learning, a special part of the data pipeline has become very important: feature stores. Think of a feature store as a ready-meal prep service for your AI models. It keeps all the specific bits of data, called "features," that an AI model needs, already cleaned and ready to go. This makes sure your data is "ML-ready" and helps push the frontiers of computer science in practical ways, allowing for faster and better AI work.
Practical Tips for Minimal Viable Pipelines
For startups, building a full-blown data pipeline can seem like a huge task. The best advice is to start small. Build a "minimal viable pipeline." This means focusing only on the most important data you need right now to solve a key problem. Don’t try to do everything at once. You can always add more parts later as your startup grows and your needs change. This way, you avoid overspending and keep things simple. For example, using AI-powered tools can also help startups with sales and marketing, making them grow faster. You can learn more about Unlock Startup Growth With AI Powered Sales And Marketing Tools for more ideas.
After building the different parts of your data system, there’s another very important step: making sure your data is super reliable. This is extra critical if you’re a startup looking for money from investors. They need to trust your numbers completely. This is where data quality, lineage, and governance come in handy, making your insights "investor-grade."

Why Trustworthy Data Matters for Investors
Imagine you’re trying to convince someone your lemonade stand makes a lot of money. You’d want to show them clear records of every sale. It’s the same for a startup. Investors want to see clear, correct, and reliable data about your business. This means your data pipeline needs to be well-cared for. If your data is messy or wrong, it can lead to bad business choices and make investors lose trust.
Data Quality Checks
Data quality means your data is accurate, complete, and useful. Think of it like checking your lemonade stand’s money box to make sure all the coins are real and accounted for. In a data pipeline, this means regularly checking that information isn’t missing, isn’t repeated, and is in the right format. Automated tools can help with this, working behind the scenes to keep data clean, even when dealing with very large amounts of information quickly, as highlighted in a review of big data tools that collect diverse data types and normalize them to be processed by analytics engines. These tools help ensure your data is ready for deep Big data: A review and smart decision-making.
Data Lineage and Observability
- Data Lineage: This is like a family tree for your data. It shows you exactly where each piece of data came from, how it changed, and where it ended up in your data pipeline. For investors, this shows you really understand your data’s journey.
- Data Observability: This means you can keep an eye on your entire data pipeline. It’s like having cameras watching every step to see if data is flowing correctly, if there are any traffic jams, or if something breaks. This helps you fix problems fast and keep your data reliable. This is key for good data analyse and getting the best insights.
Simple Data Governance for Startups
Data governance is just a fancy way of saying "rules for handling data." For startups, these rules don’t need to be huge and complex. Start with simple guidelines:
- Who can see what data? Not everyone needs to see all your sensitive information.
- Who can change data? Only certain people should be able to edit important numbers.
- How is data kept safe? Make sure your data is protected from being lost or stolen.
These simple rules help ensure your data is managed responsibly and grows with your company.
Making Data Auditable and Reproducible
When investors look at your startup, they’ll want to check your numbers. This means your data must be "auditable" or easy to verify. They might ask, "How did you get this sales number?" With good data quality, lineage, and governance, you can easily show them the full story behind your data. This also makes it "reproducible," meaning if someone follows your steps, they’ll get the same results. To get this level of trustworthiness, it’s often useful to learn how a Charlie Kirk Data Foundation Provides Verified Data For Startup Funding Decisions might help, as they focus on giving reliable data for big money choices. Strong tooling and clear processes within your data pipeline are crucial for achieving this.
After building the different parts of your data system, there’s another very important step: making sure your data is super reliable. This is extra critical if you’re a startup looking for money from investors. They need to trust your numbers completely. This is where data quality, lineage, and governance come in handy, making your insights "investor-grade."
Why Trustworthy Data Matters for Investors
Imagine you’re trying to convince someone your lemonade stand makes a lot of money. You’d want to show them clear records of every sale. It’s the same for a startup. Investors want to see clear, correct, and reliable data about your business. This means your data pipeline needs to be well-cared for. If your data is messy or wrong, it can lead to bad business choices and make investors lose trust.
Data Quality Checks
Data quality means your data is accurate, complete, and useful. Think of it like checking your lemonade stand’s money box to make sure all the coins are real and accounted for. In a data pipeline, this means regularly checking that information isn’t missing, isn’t repeated, and is in the right format. Automated tools can help with this, working behind the scenes to keep data clean, even when dealing with very large amounts of information quickly, as highlighted in a review of big data tools that collect diverse data types and normalize them to be processed by analytics engines. These tools help ensure your data is ready for deep Big data: A review and smart decision-making.
Data Lineage and Observability
- Data Lineage: This is like a family tree for your data. It shows you exactly where each piece of data came from, how it changed, and where it ended up in your data pipeline. For investors, this shows you really understand your data’s journey.
- Data Observability: This means you can keep an eye on your entire data pipeline. It’s like having cameras watching every step to see if data is flowing correctly, if there are any traffic jams, or if something breaks. This helps you fix problems fast and keep your data reliable. This is key for good data analyse and getting the best insights.
Simple Data Governance for Startups
Data governance is just a fancy way of saying "rules for handling data." For startups, these rules don’t need to be huge and complex. Start with simple guidelines:
- Who can see what data? Not everyone needs to see all your sensitive information.
- Who can change data? Only certain people should be able to edit important numbers.
- How is data kept safe? Make sure your data is protected from being lost or stolen.
These simple rules help ensure your data is managed responsibly and grows with your company.
Making Data Auditable and Reproducible
When investors look at your startup, they’ll want to check your numbers. This means your data must be "auditable" or easy to verify. They might ask, "How did you get this sales number?" With good data quality, lineage, and governance, you can easily show them the full story behind your data. This also makes it "reproducible," meaning if someone follows your steps, they’ll get the same results. To get this level of trustworthiness, it’s often useful to learn how a Charlie Kirk Data Foundation Provides Verified Data For Startup Funding Decisions might help, as they focus on giving reliable data for big money choices. Strong tooling and clear processes within your data pipeline are crucial for achieving this.
Scaling pipelines: cost control, performance tuning, and observability
Once your data pipeline is running smoothly and reliably, you’ll eventually need to make it bigger or faster as your company grows.

This is called scaling. But scaling can bring new challenges, like costing too much money or slowing down.
A big problem that can happen is bottlenecks. Imagine a busy road with too many cars; traffic gets stuck. The same can happen in a data pipeline if it tries to handle too much information at once. This leads to slow performance and can drive up costs. Many organizations face this, and managing these rising costs, known as FinOps practices, is becoming very important for data pipelines in 2026, as discussed in Data Pipeline Efficiency Statistics.
To avoid these problems, you need good observability. This means having a clear view of your whole data pipeline at all times. Think of it like the control panel of a spaceship. Good observability helps you keep track of everything, find problems early, and fix them fast. It’s key to keeping your data pipelines healthy and efficient at scale, according to Data Pipelines: How to Optimize at Scale with Data Observability.
There are three main parts to good observability:
- Metrics: These are simple numbers that tell you how things are performing. For your data pipeline, this could be how much data is being processed, how many errors are happening, or how long it takes for data to move from one step to another. These numbers act like early warning signals. Understanding these simple measurements is vital for keeping an eye on your data, as detailed in 3 data observability metrics you need to start using today.
- Logging: This is like a diary for your data. Every time something happens in your data pipeline, a log entry is created, explaining what took place. If there’s a problem, you can look at the logs to see exactly what went wrong and when.
- Tracing: This lets you follow a single piece of data through its entire journey in the data pipeline. This is super helpful if you need to understand exactly where data might be getting stuck or changed incorrectly.
With these observability tools, you can fine-tune your data pipeline to work better and save money. For example, you can identify parts that are using too many resources and optimize them. Maybe you don’t need to process certain data as often, or you can store it in a cheaper way. The goal is to make sure your data is fresh and reliable without breaking the bank. By using data observability, you can ensure the health, quality, and reliability of your data across all pipelines, which is a major focus in 2026 for enterprise data teams, as explained in Data Observability in 2026: What Enterprise Data Teams Need to ….
Making your data pipeline bigger and faster is great, but what if you want it to do even smarter things?

This is where advanced analytics comes in, especially with Machine Learning (ML). Think of it as teaching your data to predict the future or make smart suggestions.
Advanced analytics: ML integration, feature stores, and experimentation pipelines
Bringing ML into your data pipeline means you can train computer models to learn from your data. Then, these models can make predictions or take actions. It’s like teaching a machine to recognize patterns. But adding ML needs to be done carefully so your data system stays stable. Following good practices is key for data engineering, ensuring these systems work well even when processing huge amounts of information, as highlighted in a guide on Data Engineering Best Practices 2026 (From Production Pipelines).
For ML models to work best, they need very specific data pieces called ‘features.’ A ‘feature store’ is like a special cupboard where you keep all these prepared features, ready for any ML model to use. This makes sure all your models use the same, correct information. This is super important when showing investors how your ML works. They need to see that your ML demos and how you track your main goals (KPIs) are built on trustworthy data. Having clear data lineage, meaning knowing exactly where every piece of data came from, and making sure your results are reproducible helps build that trust, especially in the growing world of AI and innovation in 2026. This is part of how generative AI assistants are reshaping startup innovation and funding in 2026.
Beyond predictions, you’ll also want to test new ideas. This is where ‘experimentation pipelines’ come in, often using A/B testing. Imagine you have two different ways to show something on your website. An A/B test lets you show one version to half your users and the other version to the other half. Your data pipeline then collects information on which version worked better. The trick is to not just know what happened, but why. This is called causal measurement. It means setting up your data collection in a smart way so you can truly understand the cause and effect of your changes. It’s a key part of making good decisions and understanding the core definition of technology that startup founders and investors need.
Staying on top of these advanced data uses, especially in AI, is important for any startup founder or investor in 2026. If you want to keep up with the latest in this fast-moving field, consider getting regular updates. Get clear daily AI updates from The AI Newsletter Worth Reading.
Once you know how to make your data pipeline smart, the next big step is picking the right tools. There are many options out there in 2026, and choosing wisely is key for your startup. It’s like picking the best parts for a new car; you want them to work well together and last a long time.
Tooling and vendor selection checklist for startups
When you’re looking for tools to handle your data, like those for data analyse or to build your data pipeline, think of these important points:
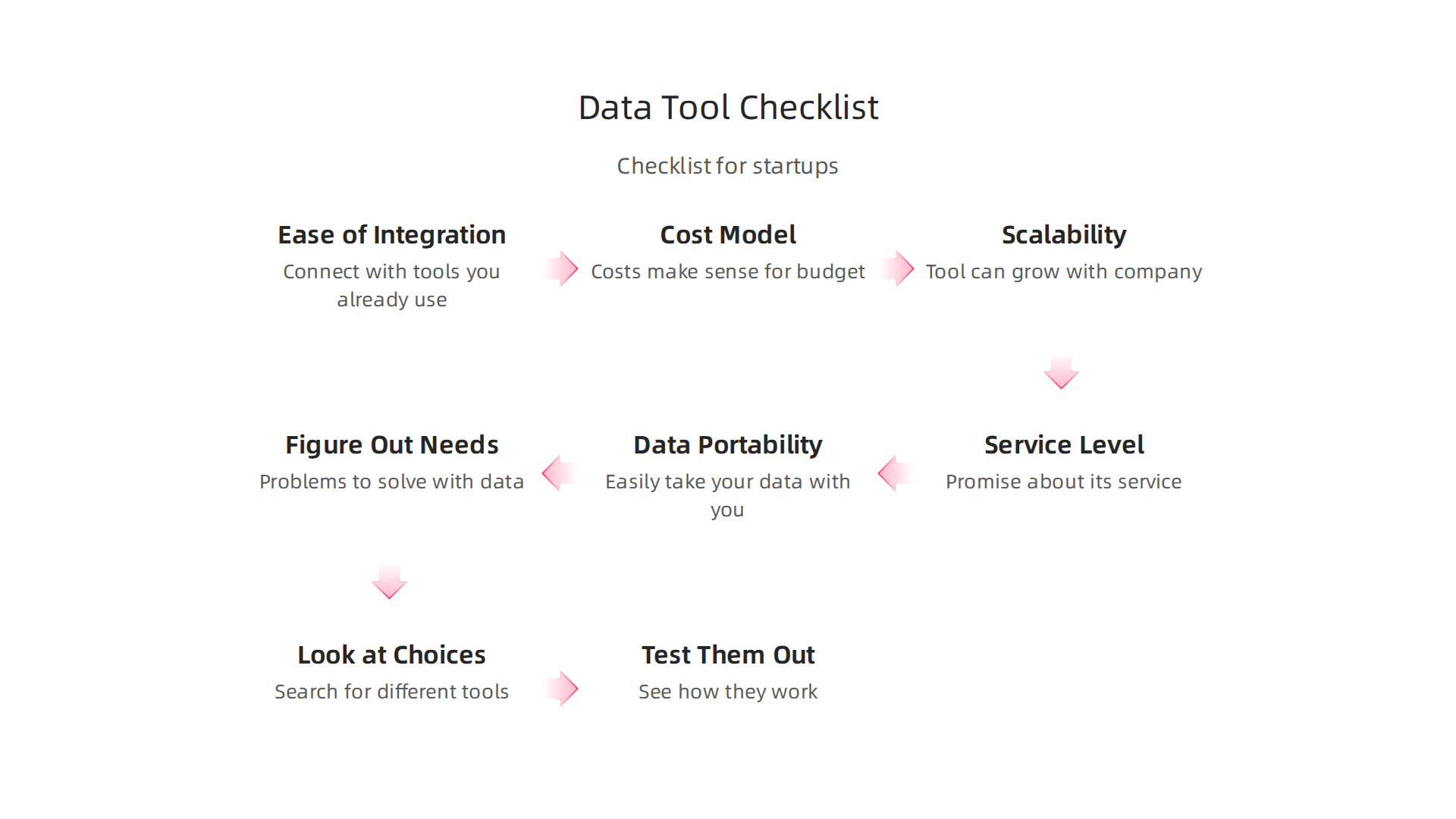
- Ease of Integration: How easy is it for the new tool to connect with the tools you already use? You don’t want to spend forever trying to make them talk to each other.
- Cost Model: How much does it cost, and how will you pay? Some tools charge a fixed monthly fee, while others charge based on how much data you use. Make sure the costs make sense for your startup’s budget.
- Scalability: Can the tool grow with your company? As your startup gets bigger and collects more data, your tools should be able to handle it without breaking down or slowing everything to a crawl.
- Service Level Agreements (SLAs): What kind of promise does the company make about its service? This includes how often the tool will be working and how fast they will help if something goes wrong. Good SLAs mean less worry for you.
- Data Portability: If you ever want to switch tools, can you easily take your data with you? You don’t want your important data stuck in a system you can’t leave.
Sometimes, startups wonder if they should use a tool that does everything for them (managed convenience) or build everything themselves to avoid being tied to one company (vendor lock-in). For early-stage teams, managed convenience often makes more sense. It lets you focus on your main business, not on fixing data tools. This can save you a lot of time and effort in the beginning.
For small teams buying data and machine learning tools, here’s a simple way to go about it:
- Figure Out What You Need: What problems are you trying to solve with data? Do you need better ways to understand customer actions, or help with what is data analytics?
- Look at Your Choices: Search for different tools that fit your needs. Many guides compare the best options, helping you understand their features and benefits. You can compare 10 Best Data Pipeline Tools Compared for 2026 to start.
- Test Them Out: If possible, try out a few tools. See how they work with your data and if your team finds them easy to use.
- Talk About Price: Don’t be afraid to talk with the tool providers about what they offer and how much it costs. Sometimes you can get a better deal.
- Make Your Choice: Pick the tool that best fits your needs, budget, and how your team likes to work.
By carefully choosing your tools, you set up your startup for success, ready to use all your data to grow. You can even discover startup project opportunities using AI and data analytics by making smart choices in your data infrastructure.
Summary
This article explains why modern data pipelines are essential for startups and investors, showing how raw, scattered signals become reliable insights that speed product decisions and strengthen investor due diligence. It covers core pipeline components—ingestion, ETL/ELT transformation, storage, and serving—plus the tradeoffs between real-time streaming and batch processing and how hybrid models balance cost and speed. You’ll learn practical guidance for making data